Table of Contents
Introduction
At Eastern University’s Master of Science in Data Science Capstone course (DTSC-691), you are required to write up a proposal for a data science project. I actually evaluated several ideas before deciding on the one that I went with. One of those ideas I carried as far as writing a proposal and doing the data cleaning. I eventually abandoned the project for a few reasons (the data was so unreliable that I was concerned I wouldn’t be able to make a proper prediction, mostly.)
The proposal is very similar in structure and content to my actual approved proposal, although the approved project is a totally unrelated area and the data cleaning and model choices, etc., are all different.
Because I wrote this proposal myself and it was never submitted for credit or otherwise evaluated in any way, I figure it stands as a useful resource for future DTSC-691 students who are curious what a proposal might look like.
Note that I did minimal review since I abandoned this project before submission so there may be errors in my statistical approach, etc., that I haven’t ironed out. Buyer beware. Also, while you’re welcome to learn from this proposal keep in mind the Eastern University Academic Honesty and Integrity policy.
DTSC 691 Project Proposal
Dustin MacDonald
Identifying Factors Relevant to Nonprofit Collapse: A Machine Learning Approach
Executive Summary
| Machine Learning Problem Type | Classification |
| Goal of Project | Classify whether nonprofits will fail in the next 12 months |
| Type of Machine Learning | Supervised Learning |
| Dataset | IRS Form 990s |
| Feature Selection | Backward Elimination |
| Class Imbalance Remedy | SMOTE |
| Model Selection | Decision Tree Logistic Regression Random Forest Support Vector Machine |
| Model Evaluation | F1 Score Matthew’s Coefficient Correlation |
Goals of the Project
Motivation
The purpose of this project is to develop a machine learning model capable of predicting whether a nonprofit organization will fail within the next year. This is valuable because individuals choosing to support nonprofit organizations want to support strong, successful organizations that are likely to continue to achieve their mission. Additionally, if we understand what kind of factors lead to an organization’s collapse or failure, those can be mitigated to reduce the likelihood of failure.
Nonprofit organizations commonly fail for a few reasons, including a lack of funds, the departure of a key staff member, or fraud/corruption. (Levine, 1978 as cited in Arbogust, 2020) Other reasons that an organization may wind up include merger with another organization or the organization’s mission having been completed. The goal will be to identify which factors in the Form 990 appear most important to the outcome.
This work will also complement and extend the work of Arbogust (2020) who completed a quantitative review of the factors leading to nonprofit closure in organizations that existed in 2014 but failed by 2016 in Virginia, DC, Maryland, Pennsylvania, Delaware, New Jersey and New York.
Because of the method of data collection and analysis used in that study, only 102 organizations met the criteria out of the approximately 1.5 million nonprofits in the US. While many of those 1.5 million nonprofits are under the $50,000 threshold requiring the filing of a Form 990 there is still an enormous dataset going un-examined and a significant advantage to be gained by using machine learning to conduct a deeper analysis than would be possible by hand.
By conducting a similar analysis to that of Arbogust before extending their analysis to a wider group of nonprofits, there will be an opportunity to verify their findings while producing a tool that can be provided with Form 990 data on any 501(c)(3) organization and predict whether it will fail.
Research Question Statement
Are there organizational, financial or governance data available on the Form 990 that are predictive of a nonprofit organization’s collapse?
Hypothesis Formation
The hypotheses from the Arbogust study will be used as an initial validation step. That study examined 3 hypotheses with 14 specific conditions:
- H1: Financial indicators for failed nonprofit organizations differ from those of sustainable nonprofit organizations.
- H2: Governance indicators for failed nonprofit organizations differ from those of sustainable nonprofit organizations.
- H3: Failed nonprofit organizations will exhibit deteriorating governance and financial factors in the years preceding closure.
The specific conditions included, for example, H1A, “Failed nonprofit organizations will exhibit significantly less sufficient equity than successful nonprofit organizations.” Two-sample t-tests were used to test these specific hypotheses.
Additionally, the overall project hypothesis is that there is a set of criteria that can sufficiently differentiate nonprofit organizations that will fail with sufficient predictive validity. (H4)
The response variable will be a single binary classification of nonprofit success or failure. An additional outcome will be a set of variables that are predictive of a nonprofit’s success or failure in the form of a decision tree or other classification algorithm.
Hypothesis Testing
For hypotheses H1, H2 and H3, I will proceed with two sample t-tests to determine if there is a statistically significant difference between the organizations that fail or not, on the basis of finance or governance. All t-tests will use a p-value < 0.05 to reject the null hypothesis.
To determine whether hypothesis H4 is met, I will aim to build a machine learning model that reaches a reasonable level of predictive accuracy, with an F1 score (Lipton, Elkan, & Naryanaswamy, 2014) of 0.70 or higher representing moderate predictiveness and Matthew’s Coefficient Correlation (MCC; Chicco & Jurman, 2020) of +0.60 or higher.
Materials and Methods
The IRS requires nonprofits to file a Form 990 (Return of Organization Exempt from Income Tax) yearly. This document collects information about the organization’s finances, key leadership, and activities throughout the year. (IRS, 2022)
The IRS provides these Form 990s searchable by organization online and also as XML and PDF exports. The project will involve extracting the relevant information from Form 990s over a 4-year period (based on available data) in order to identify which organizations failed or succeeded and then to see what factors may have contributed to this.
Model Selection
A variety of models will be tested in order to maximize the predictive validity of the model. This is an imbalanced classification problem. If failure is classified as 1 and non-failure is classified as 0, the model should prioritize reducing false negatives. The failure of a nonprofit that was not expected to fail is a bigger risk than falsely predicting a nonprofit would fail that eventually survives. For this reason we will be trying to maximize recall.
Models that will be explored include logistic regression, support vector machine (SVM), decision trees, and Random Forest. Although a time series model like Cox proportional hazards (Fox & Weisberg, 2011) would take most advantage of the data being available over time, logistic regression and similar models have been effective in working with time series data. (van der Net, et. al., 2008) If it is feasible, an attempt will be made to use a time series library like sktime, in order to compare and contrast non-time-based models with the time series ones.
Feature Selection and Engineering
To determine the most relevant features, backwards elimination will be used. With this method, a linear regression model is fit on the complete set of features. Then the p value is calculated and the adjusted R2 is determined. Any features with a p value above 0.05 is removed and the regression repeated until there is no additional increase in the adjusted R2.
Model Training and Evaluation
A train-test split will be used with 80% of the data used for training and 20% used for testing. The dataset is large enough that machine learning models selected should all have an opportunity to learn from a sufficiently wide set of data.
To compare the different models, receiver operating characteristic (ROC) curves will be plotted and the area under the curve (AUC; Ling, Huang & Zhang, 2003) will be used. To evaluate the final model chosen, the F1 score and Matthew’s Coefficient Correlation score will be used.
Hyperparameter Optimization
Grid Search with cross validation will be used to determine the optimal hyperparameters.
Deliverables
The primary deliverables will be a Flask-based web application that can accept the Form 990 inputs and provide a prediction as to whether the nonprofit will fail in the next 12 months. Potentially, this may be expanded to allow uploading of the data directly in the form of a PDF or other format.
Additionally, a medium-term goal will be to write up the results for publication in Nonprofit and Voluntary Sector Quarterly or a similar peer-reviewed journal. Notably, Arbogust’s analysis was never published in this forum and therefore there is a gap in the literature.
Implementation Strategy
The data has been downloaded from the IRS Web Portal. The data will be parsed and read into a dataframe by year. Returns with a return type of “990EZ” or “990PF” will be dropped because these are not full-data charitable returns.
Additionally, any return that does not have an element node of “Organization501c3Ind” will be excluded because other nonprofit organizations (e.g. 501(c)(6) Chambers of Commerce of 527 Political Organizations operate differently.)
Organizations that appear in one year’s 990 but do not appear in any future years will be coded as having failed. This was the same strategy used by Arbogust. Because the IRS is still processing returns from April 2020 and later, only data from 2015-2017 will be examined. All nonprofit organizations must file returns yearly or else face automatic dissolution by the IRS after 3 years.
Because this is a class imbalance problem where most samples fall into one category (in this case, they did NOT fail), we will use SMOTE (Chawla, Bowyer, Hall, & Kegelmeyer 2002) to add additional samples to the training set to improve the predictiveness.
Backward elimination will be used to eliminate features before several models are tested. GridSearch with cross-validation will be used to determine optimal hyperparameters before a final model is decided on.
Data Description
The Form 990s have been downloaded from the IRS website (IRS, 2021) and extracted. There is data available in XML format, stored as evenly sized ZIP files from 2015-2022. Only data from 2015-2017 will be used. This will be converted into a dataframe so that it can be examined.
There is approximately 26GB of XML data.
Except for the final extract of the year, each of the ZIP files is approximately 400MB compressed and 2GB uncompressed, containing 65,000 returns in an individual XML file.
Example of XML Data viewed in the browser
This means there is in excess of 1.8 million returns to be processed. Of the total number of returns across all years, 1,018,849 of those are Form 990s as opposed to Form 990EZ filed by small organizations or Form 990PF filed by Private Foundations.
Of the Form 990s, 774,585 are for 501(c)(3) organizations. These will compromise the final dataset. Note that many of these will not be usable due to data quality issues (e.g. in a sample of 1000 nonprofits from this final dataset, 358 were missing Form 990s for at least one year but had them in the next year. These organizations would automatically be excluded due to inability to code them as failed properly. )
Due to the length of time that row-wise operations take, a stratified sampling approach may be used where, for example, 5000 rows are drawn from 2014, balanced between the two classes (meaning that samples continue to be drawn randomly until enough of both classes are available) and then followed for the 4 years in order to ensure a large enough dataset to train a model without overwhelming available computing resources.
Once the model is developed, it will be tested on the complete dataset (with a test train split) to ensure it is still accurate.
| Type of Return | Total | Total (%) |
| Non-990 | 795,237 | 43.8% |
| Form 990, not 501(c)(3) | 244,264 | 13.5% |
| Form 990, 501(c)(3) | 774,585 | 42.7% |
| Grand Total | 1,814,086 | 100% |
The exact number of features is hard to determine in advance. There are approximately 660 data points on the Form 990 (https://www.irs.gov/pub/irs-pdf/f990.pdf) however many of these will not be relevant in the analysis.
Examples of Features that will likely be retained:
- State
- Was a Paid Preparer Used?
- Is the organization offering significantly new programs or services?
- Did the organization cease conducting, or make significant changes in how it conducts, any program services?
- Current Year Total Revenue
- Previous Year Total Revenue
- Current Year Total Expenses
- Previous Year Total Expenses
- Current Year Salaries
- Change From Previous Year Revenue (this will be derived)
- Change From Previous Year Expenses (this will be derived)
- Current Year Net Assets/Fund Balances
- Previous Year Net Assets/Fund Balances
- Compensation of Board Members
- Number of Board Members
Arbogust’s dissertation used 2014-2016 data. Unfortunately, 2014 Form 990 submission data is not available in XML. For that reason I am focusing on the data already available in XML format from 2015-2017.
Since nonprofit collapse is the less common outcome among organizations large enough to file a 990, with between 10 and 30% ceasing to exist in 10 years (Harrison & Laincz, 2008, Harold, 2020), it’s important to remedy class imbalance so that a machine learning model will maintain sufficient recall as to be useful.
Data Preparation and Cleaning
The data is relatively clean (except for some data entry differences like using 0 or False in a column), but reading the XML requires building a custom XML parser to traverse through the document structure, extract the necessary data and put it into a dataframe before being coded. This is being accomplished with the ElementTree library and a series of lists and dataframes.

Example of parsing the XML using ElementTree
All column names contain extraneous text like “{http://www.irs.gov/efile}.” that must be removed.
Unnecessary columns will be dropped. Additional columns may be derived as needed. (For example, the previous year and current year assets are provided but not the percentage change in those values which may be more relevant.)
As mentioned previously, any nonprofits that are not 501(c)(3) charities with gross receipts above $50,000 a year will be excluded, because these organizations file somewhat different returns included in the dataset that are not useful for the analysis.
Missing data will likely not be imputed given the difficulty of estimating things like expenses or salaries which can vary wildly between different organizations. Instead, only records containing all of the desired features will be retained.
There is the possibility that this may alter the analysis (e.g. organizations that are likely to fail may due to a poor job of preparing their Form 990s leading to missing values.)
The dask library may be used to allow the manipulation of datasets bigger than computer memory allows.
Outcome
The major outcome of the project is a model that can classify if a nonprofit organization will fail in the next year. Using Flask, this will be made available as a website to enter the features from the Form 990 that are relevant to the model (or perhaps, if the project goes especially smoothly, as a web interface to upload the Form 990 for direct parsing.)
Software
For this project, software used will include Spyder and Jupyter Notebook for the writing and testing of the Python code along with libraries including scikit-learn, matplotlib, pandas, ElementTree (for parsing the XML) and potentially dask (for chunking of the 30GB of data to allow analysis on a single computer.) Flask will be used to create a web-based frontend for the project.
R/RStudio may be used to confirm the output of the statistical tests, and LaTex for the final report preparation. Amazon’s EC2 may be used to speed up the Grid Search.
Analysis Plan
- Obtain Data (Week 0)
- This part is already done. The data has been downloaded and extracted.
- Data Preparation (Weeks 1, 2, 3)
- I’ve already written a set of data cleaning functions that effectively separates the Form 990s from the other records in the set, identifies the 501(c)(3) records and extracts the features I will need from them (100+) into a dataframe.
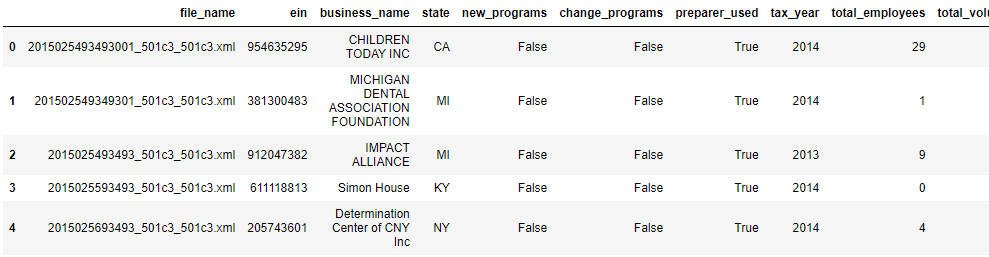
Example of parsed data put into a dataframe
- Additional data cleaning will be necessary to get the records ready, for example some records contain the strings “True” or “False”, or the numbers 1 or 0. These will be changed to booleans.
- Other data cleaning will involve ensuring all dollar amounts are converted to numerical values (from strings), and excluding any records outside the desired window. For example, some records processed in calendar year 2015 were delayed submissions from the 2013 tax year. These records will be dropped from the analysis.
- Additionally, some nonprofits have inconsistent records – for example a record in 2015, no submission in 2016, and a record in 2017. These will be excluded because they would be incorrectly coded as “Failed” when they have not.
- One Hot Encoding will be used on the categorical values while revenue and other numerical data will be centered and scaled
- Hypothesis Formation (Week 3) – this part is done (see above)
- Hypothesis Testing (Week 4)
- Development of Machine Learning Model (Weeks 4, 5)
- As noted above, several models for both time-based and non-time-based classification will be used
- Model Evaluation (Week 5)
- Deliverable Preparation (Week 6)
- Project Completion and Distribution (Week 7)
Limitations
The primary limitations will be based on the quality of the Form 990 data. It is known that it can be unreliable, especially in smaller organizations already more prone to failure, because they may choose to save money by not using an outsider preparer, increasing the risk of errors.
The other limitation is around the choice to use listwise data deletion, since there is no way to know if data is missing in specific fields because of factors affecting the ultimate analysis. For example, an organization that makes poor quality data available in their Form 990 may be more likely to collapse but we would be unable to tell because the lack of data precludes the analysis.
References
Arbogust, MacKenzie. (2020) “Why Do Nonprofits Fail? A Quantitative Study of Form 990 Information in the Years Preceding Closure”. Doctor of Philosophy (PhD), Dissertation, School of Public Service, Old Dominion University, DOI: 10.25777/n8yg-9475 https://digitalcommons.odu.edu/publicservice_etds/45
Chawla, N.V., Bowyer, K.W., Hall, L.O. & Kegelmeyer, W.P. (2002) SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research. 321-367.
Chicco, D., Jurman, G. (2020) The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics. 21(6) https://doi.org/10.1186/s12864-019-6413-7
Fox, J. & Weisberg, S. (2011) Cox Proportional-Hazards Regression for Survival Data in R. Appendix to An R Companion to Applied Regression. Sage, Thousand Oaks, CA, second edition.
Harold, J. (2020) How many nonprofits will shut their doors? Candid. Retrieved from https://blog.candid.org/post/how-many-nonprofits-will-shut-their-doors/
Harrison, T.D. & Laincz, C.A. (2008) Entry and Exit in the Nonprofit Sector,” B.E. Journal of Economic Analysis & Policy. 8(1).
Internal Revenue Service. (2021) Form 990 Series Downloads. Retrieved from https://www.irs.gov/charities-non-profits/form-990-series-downloads
Internal Revenue Service. (2022) Form 990 Resources and Tools. Retrieved from https://www.irs.gov/charities-non-profits/form-990-resources-and-tools
Levine, C.H. (1978). Organizational decline and cutback management. Public Administration Review, 38, 316-25.
Lipton, Z. C., Elkan, C., & Naryanaswamy, B. (2014). Optimal Thresholding of Classifiers to Maximize F1 Measure. In T. Calders, F. Esposito, E. Hüllermeier, & R. Meo (Eds.), Machine Learning and Knowledge Discovery in Databases (pp. 225–239). Springer Berlin Heidelberg.
van der Net, J., Janssens, A., Eijkemans, M. Kastelein, J.J.P, Sijbrands, E.J.G. & Steyerberg, E.W. (2008) Cox proportional hazards models have more statistical power than logistic regression models in cross-sectional genetic association studies. Eur J Hum Genet 16, 1111–1116. https://doi.org/10.1038/ejhg.2008.59
Hello Dustin,
Thanks for sharing. I have a couple of questions:
1. Did you learn Flask on your own, or does Eastern offer a short block of instruction on it?
2. Did you present your project to an audience, or did you simply submit it for evaluation?
After reading several articles on your blog, I sense there has been tremendous growth in your journey to earn your master’s in data science. Congratulations.
Hi R A,
Thanks for writing. Eastern does not offer much direct instruction on Flask. They do link to a quite lengthy tutorial on the subject. I think I’ll be writing an article on Flask soon. It’s really not as complicated as it seems at first, but a lot of tutorials are either way too detail-heavy, or they include no details at all and just tell you what to do without explaining why you need to do it. Once my project is approved, I’ll use the code as the basis for that.
I did experiment briefly with Heroku and was able to get a different project working there, but I did not try to get this project there because to take a standard Python project and wire it up with Flask involves replacing several crucial elements with Flask code, and then to deploy it with Heroku involved a second set of replacements which I felt was too much in the limited amount of time I had.
For the presentation itself, we record a max 30 minute walk-through video (mine was 21 minutes) where you walk through your code and explain the different decisions you made. You also upload a copy of your code and data where your assigned mentor (who reviewed/approval the proposal) and the course professor can see it. Finally, you submit a Project Submission which is a more detailed version of your course proposal, replacing the “what if’s” and the plans with the actual work that you completed.
Dustin
Thanks for the response.
Since you’ve gone down the Flask hole, the suggestion of StreamLit is for naught. However, others who may read this blog in the future may want to add it to their list of possibilities. Supposedly, StreamLit is easy to use and is geared toward creating data science Web apps.